Knowing about the standard library functions in Kotlin saves a lot of time while working on complex data structures. Whether you are mapping the API response model into your business model or you are sorting, filtering, and manipulating data; knowing these operation on Kotlin collections come really handy.
In this post, we are gonna go through some collection transformation operations that I use frequently.
Kotlin Collections – Transformation Operations
1. Mapping

Mapping means to modify each item in a collection by applying a transformation lambda which results in the creation of another collection.
If you are working on lists of data that you need to transform from one model into another or if you want to convert the API response model into a domain layer model you should use mapping operations in Kotlin.
.map()
Using the .map() function is the most common way to convert a collection of items into another. It applies the given transform lambda to each of the items of the receiver collection and yields them into a newly created list.
.mapIndexed()
If you also need the index of each item when transforming them, you can use the .mapIndexed() function. It will feed the index of each item to the transform lambda so that you can utilize the order of the items.
.mapNotNull()
Another convenient mapping function is .mapNotNull(). You can use it if you want to filter out null items after the conversion.
For example, if you have a list of objects which may or may not have text property, you can use .mapNotNull() to get a list of texts without any nulls being in it.
—
Kotlin’s standard library also has .mapIndexedNotNull() method which combines .mapIndexed() and .mapNotNull().
Also you can find .mapKeys() and .mapValues() methods which are defined on Maps.
Please check out the official documentation if you need more information on the topic.
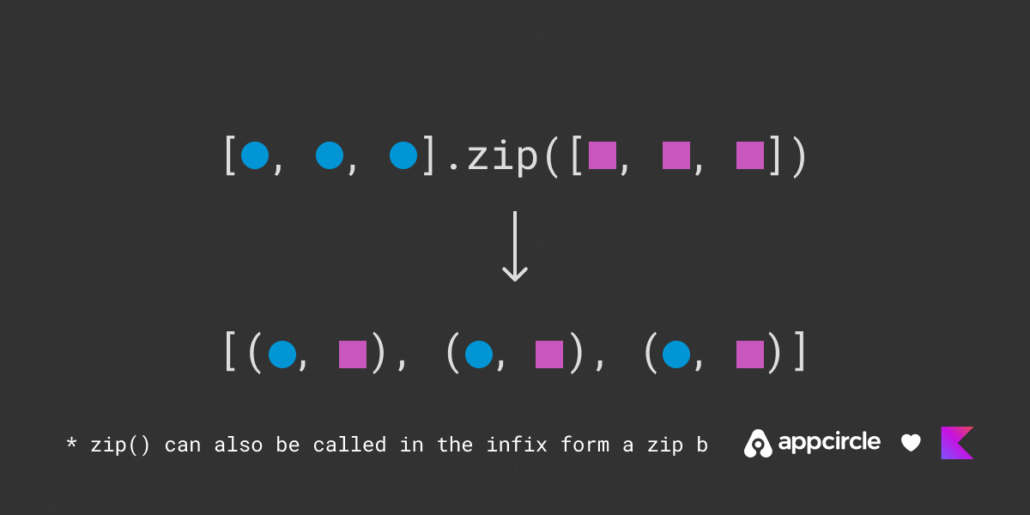
2. Zipping
When you have two lists of the same size and you want to merge each item from the first list with the corresponding item coming from the second list you want zipping.
Kotlin standard library has convenient functions to zip and unzip collections including Lists, Arrays, and Sequences.
Let’s take a look at what we have:
.zip()
You can use .zip() without any transformation to create a list of pairs. The pairs have their first item from the receiver list and the second from the argument. If you want to combine two different data sources into one and if the sources has the same number of items, the function .zip() is really useful.
.zip() with transform lambda
If you don’t need pairs but you want to define your own zipping logic, good news: .zip() can also take a transform lambda as an argument. So you don’t need to chain a .zip() command with a .map(). Instead, pass a lambda and combine two items coming from two data sources in a way you would prefer.
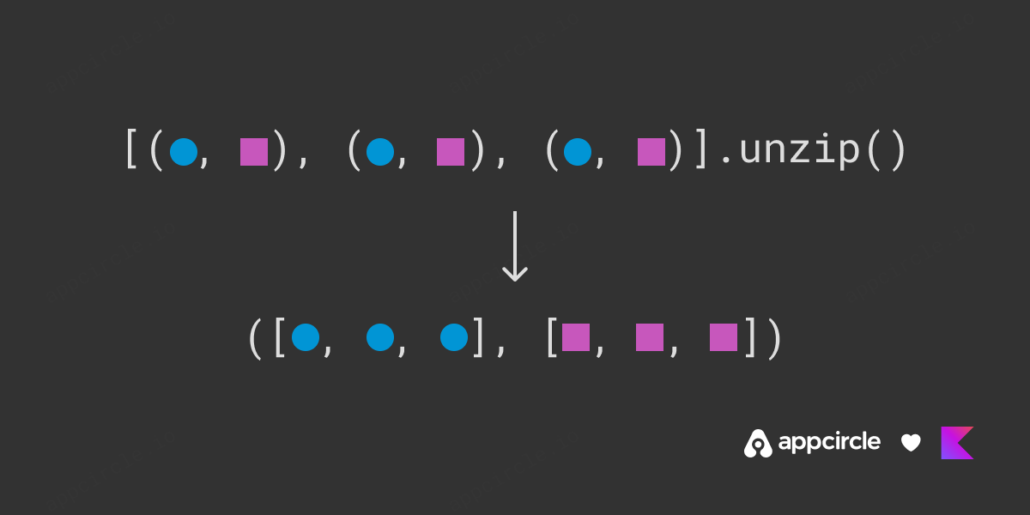
.unzip()
Another great function in Kotlin is the .unzip(). The name gives it all away: it does the opposite of .zip(). If you have a list of pairs and want to create two lists that contain the firsts and seconds of each item, then just .unzip() it!
—
If you want to see some examples please check out the official documentation.
Now let’s check out another group of transformation operations:
3. Association
Association is when you want to traverse a List and convert it into a Map by associating each item with one of its properties. Understanding association operations is easier to show than tell, so let’s take a look at what sort of functions we have in the standard library:
.associateWith()
The .associateWith() function, structures the items of the List as keys of a Map. The values for each key are computed by running the given lambda on the item. Please note that maps cannot have duplicate keys, so if the receiver collection has repetitive items, only the last one will remain in the map.
.associateBy()
Kotlin also has .associateBy(), which functions almost the same. The difference is items of the receiver collections are not used as keys but values.
That means if the lambda returns the same values for different items, only the last one will be present in the resulting map.
.associate()
The last associating function in the standard library is .associate().
Using this function, you can define the logic of building the map. You need to pass a lambda that returns Pairs and a Map will be built for you using these Pairs.
Please note that this function has some performance implications since it generates Pairs as an intermediate step.
—
If you want to learn more on association you can take a look at the official documentation.
Now, let’s see how we can flatten collections:
4. Flattening
Flattening in general is removing the nestedness in a collection. Consider you are given a list of lists. If you want to remove all child lists and get their elements into one single-level list, you need to flatten that list.
Let’s begin with:
.flatten()
This is the most simple way of flattening a list of lists into just list. Just call .flatten() on the receiver collection to have a flat list.
.flatMap()
Or, if you want to apply some kind of transformation whilst flattening, you can use .flatMap().
Please note that .flatMap() is just a shorter form of .map().flatten() chain.
—
If you want to see some code examples, you may check the official documentation on flattening.
Now let’s check out last chapter:
5. String Representation
If you are generating user-visible text out of Kotlin collections or trying to log an internal state you will need to represent collections as strings. I really liked when I learned that Kotlin standard library has a function just for this reason:
.joinToString()
If don’t pass any parameters to .joinToString(), string representations of each items will be concatenated in a string and separated by commas with spaces by default.
Customizing the separator, prefix and postfix strings
However, if you need to change the separator strings or add some more useful information to the start or to the end you can pass some arguments for separator, prefix and postfix parameters.
The limit and truncated arguments
.joinToString() also support limiting and truncating the list. If you have a long list and don’t want to print everything and make a mess, you can limit how many elements you want in the resulting string and what string to use in the place of an ellipsis.
Finally, it also supports passing a transform lambda if you also want to define how each item will be converted into a string.
You can study the official Kotlin documentation to learn more about the topic.
That was it! Now you have learned how to transform Kotlin collections using a handful of convenience functions.
If you like the article please share in your social media and if you want to learn more on Kotlin’s standard library functions, let us know!
FAQs
1. What are collections in Kotlin used for?
Kotlin collections are used to manage and manipulate groups of objects or data efficiently. They allow developers to store multiple values of the same type in a structured way and offer powerful tools for adding, removing, sorting, filtering, and transforming data.
2. What is the difference between array and collection in Kotlin?
In Kotlin, an array is a fixed-size container that holds elements of the same type, while collections are more flexible and feature-rich. Collections like List, Set, and Map offer advanced capabilities such as immutability, transformation, and function chaining, making them well-suited for handling complex data in modern Kotlin development.
3. What are the three different types of collections?
Kotlin provides three main types of collections:
List: An ordered collection that allows duplicate elements.
Set: An unordered collection that only includes unique elements.
Map: A collection of key-value pairs for associating and retrieving data.
Each of these collection types comes in both mutable and immutable forms, giving you precise control over how data is modified or protected throughout your Kotlin projects.